The future of research: tech-enabled services
Presented in partnership with a16z at NY Tech Week, June 2024
Victoria: The star of the show today is Ainesh, our head of product here at Wonder. He'll kick things off with an introduction and share more of his background both before Wonder, and over the last almost decade building the company. But today's conversation is really about tech-enabled services and, specifically, how we see it transforming the whole research space.
We're excited for a very rich conversation! I've gotten messages from a number of attendees around either questions or just how you're thinking about this space, so we'd love for this to be as much of a conversation as it is a useful 55 or so minutes for you. Over to you – take it away!
Ainesh: Amazing! I'm actually out in SF this week for Snowflake Summit, here with a bunch of different AI leaders chatting through what the future of AI and data, especially for the enterprise, look like.
I'm going to share my screen and we're going to chat through some of the things that are top of mind, specifically around tech-enabled services.
Before that, a little bit about me.

I've been building Wonder for the last seven or so years now. We started getting into AI before AI was cool, back in 2018, 2019. Then we realized the technology wasn't quite good enough yet at that point. We ended up saying “You know what? We have to go much more of the human driven approach for a bit until the AI models get a lot better.” Which was really when OpenAI launched that first series of 3.5 and 4.0 models.
Before Wonder, I was at AMEX for a bit. I also taught the GMAT and, in a past life, studied computational biology at Penn. I was really into the hackathon scene there (and really the hackathon scene anywhere – I love building things). You may have seen some of my stuff on LinkedIn, where I like to post a lot about tech-enabled services, RAG, AI, how that's changing, how we can apply AI specifically to the enterprise problem space, etc.
On to today's game plan.

A few things we're going to cover:
The research landscape in 2024,
The state of AI, research and the union between them,
Then we'll get into tech-enabled services, where we’ll spend a lot of our time.
And then we'll take a peek under the hood and go inside the lab, where I'll share more about how we make AI work better for us at Wonder.
Lastly, we'll have some time at the end for Q&A.
To start: the research landscape in 2024!
This piece is timeless, right?

We know that more, better questions are the lifeblood of business growth since the inception of businesses. And really since the inception of humanity, more, better questions lead to better insights and better answers. And those better insights and better answers will lead to the better decisions that you end up making on the micro, the stronger strategies you end up making overall as a team, and then the smarter bets that your company ends up making as a whole.
But then we also know that this space is crowded, right?
There are endless ways to answer business questions, close knowledge gaps, and find new opportunities. You can see all the different spokes here:
Company and competitor intel and a series of different vendors in there.
Behavioral and attitudinal insights, and different ways you can get all of these different insights and the connections between them.
Different ways that you can bring in social listening.
Primary research has its own set of options, from vendors you can use to in-depth interviews that you can go through.
And then you have the desk and secondary research area.
So now the question is, between all of these different things, how do you piece all of these together to close knowledge gaps and identify opportunities?

What we realized is that they all required trade-offs that no professional should ever have to make – between being fast vs. being in depth and a little bit slower; between being affordable and more expensive.
Do you want the broad landscape or a really deep dive? We know that consultants typically like broad overviews, but hedge funds need the inch wide, mile deep research. It's really just a cluster out there, right? There are so many different ways to go about this and then so many different pieces within the level of fidelity you need as someone that works in the enterprise to be able to make decisions.
Sometimes you actually just need something directional. So, you know what? ChatGPT is great.
Other times, you need something that's more than 60% there, right?
Then when we think about full service vendors, they also come with their own drawbacks.

You have the technology “productivity tools” that are incomplete and a little bit more do it yourself: the ChatGPTs, Geminis, Perplexities, Claude series, and their competitors. You have a series of different things where you are the “human in the loop” so to speak with that technology tool. It can help you get maybe 10% productivity gains, but you actually end up having to do most of the work yourself.
Next here is the freelance market and that wave that really cropped up over the past 10 or so years, where you have a contractor you can find on Upwork or on Fiverr or a slightly more managed service like Catalant. You have to go through the vetting and the hiring and the process of making sure that you have the right person. And then from there, there's no guarantee on the quality that you might receive.
And then on the high end, you have the McKinseys of the world – Bain, BCG, Accenture, all of these different strategy consulting firms – that are really amazing and get you what you need, but they're extremely costly, right? So they’re only usable by a certain part of the enterprise and for a certain class of problems (typically for the c-suite for the big bets that they might be making each year).
But what about all of the smaller questions that innovation teams have, or the random questions that come up that you just can't necessarily get a McKinsey engagement for? That's where we see a lot of the opportunity for AI to step in.
I'm going to segue into this next segment: what is the state of AI as it relates to research and what are the promises as well as the drawbacks?
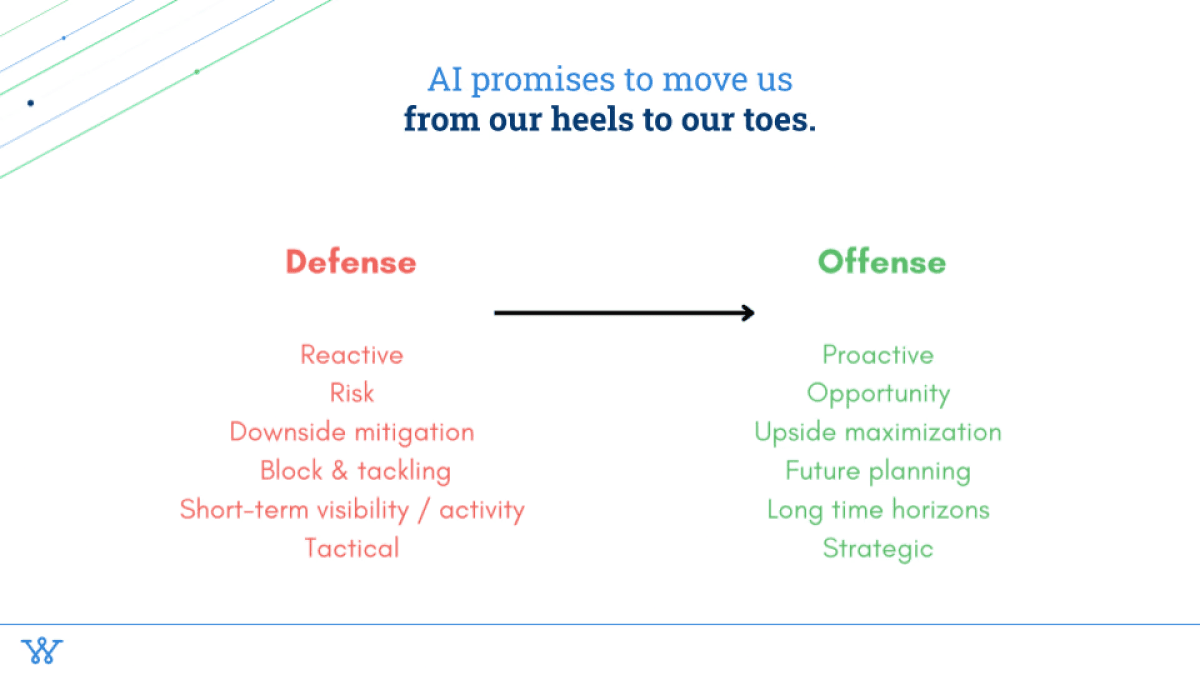
First the promises. We're in this real-time multi-player strategy game, which is business. It's never been faster. And the promise of AI is to help us move from our heels onto our toes so that we can be a lot more proactive in the strategies that we have, and go from playing defense and being reactive (downside mitigation, blocking and tackling, a lot more of the tactical things) to really focus on “How do we now go to our toes? How do we be a lot more proactive with the opportunities that we decide to pursue? How do we look at topline growth and look at all of the different white spaces that we can play in to figure out: Who do we serve? Where do we play? And how do we win?”
And then finally on the long-term horizons: the more and more that we can be on our toes, the further and further we can look out and try to make stronger bets in the future.
So those are the promises of AI. And we're already seeing across the research industry, across different verticals within it, they've already started to adopt a bunch of these AI capabilities.

On the desk research side, horsepower and speed are a lot of the benefits. On the behavioral side, predictive insights – more pattern recognition. On the social side: how do you get earlier signals? Can we get signals off of a day's worth of data versus a month's worth of data?
Another one that I want to call out here specifically is in repositories: there's a lot of players. I was just at S&P's presentation here at the Snowflake Data Summit, where they're walking through their ML pipeline of effectively how they mine the public web for insights that then get repackaged up. We're starting to see a lot of repositories and a lot of data players playing in that space.
But another thing that we know is that consumer AI is not the same as enterprise AI.

For consumer AI, you might be okay with it being right 50% of the time. In enterprise AI, that's just not the case. That's just not feasible, right? You can't make a bet on something that's less than 95% accurate.
And that’s where AI breaks.

AI can be such an amazing hackathon project, it can be such an amazing demo that anyone can create and show the promise. But to actually productionize something – to make it enterprise grade, to make it something you can make a million or billion dollar decision on – requires a lot more fidelity and a lot more testing.
Some of the pitfalls where AI falls short?
You can think of it as the world's best pattern matcher. A lot of the things that get pattern matched today by humans will then get matched by AI.
So discriminatory practices that exist that lead to flawed algorithms? That needs some level of human oversight. The black box nature, which we're starting to see a bit more motion here where a lot more application layer companies are showing the work that goes into all of the insights that we're getting.
You have Perplexity showing sources. What we tend to do is look at the individual step in the chain that we can pull, and show our work to make the research process much more defensible by showcasing not only where the source was, but what we did with the calculations from the underlying source.
In house AI expertise: again, we're starting to see a little bit more democratization of this, in terms of different UIs to access AI such that you don't need to be an AI expert. If we rewind 10 years, the only way AI was accessible was if you were a deep ML or AI researcher. Then you got into the AI engineers that were able to start to work with some of these models. With OpenAI and with Claude – all of these different LLMs that are out there – you needed to be an engineer to access the power of AI. And then you start to get a wrapper on top of that, which now lets business users access AI. So we're getting more and more to the world where AI expertise isn't as necessary.
But AI curiosity and how it can be applied IS necessary.
Another piece in here is how do we not automate everything away? We need to think through how we did that thing in order to be faster with any questions that get asked, so that we can make decisions. Not automating away our whole prefrontal cortex and the work that goes into it.
A couple other pieces around emerging stuff, the new pieces: AI is, again, a great pattern matcher. On the emerging stuff, it's a bit tougher. There's also a ton of talk right now about synthetic data and the promise of it – a lot of really cool work is being done in this space.
We're not at a point where modeling black swan events is something that is a simple problem. There's already some level of negotiating down in the industry to call it “gray swan” events that could possibly be predictable. But we’re still seeing black swan events which tend to have the biggest and longest-lasting impact being a place that requires a lot more research.
Victoria: We had a question around the definition of application layer and application layer company.
Ainesh: Actually, a great segue to this slide, which I'll touch on a little bit more later. What are the different players here?
You have the hardware companies (the NVIDIAs, the AMDs): they actually build the underlying GPUs that the model companies are built off of. The model companies are your OpenAIs, your Anthropics, obviously big tech players like Google with Gemini, AWS and their series of bedrock models that they're making more available.
Then, upon those, you have the data layer. These are different data providers that have access to a bunch of different data that can be used either to train models or they can use applications on top of it to make their applications better. When I say the “application layer” it's actually a pretty wide breadth – with any LLM app that exists (Wonder being one of them), how do you effectively combine all of the different underlying pieces between the data model and the hardware to then create something that drives business value?
So any sort of application (like ChatGPT) sits on the application layer. Anything that we would interact with to then get some level of business value would sit on the application. Another example would be Midjourney for design, where obviously they use all of the underlying models, but in a little bit different way, and they tailor it to a specific use case.
I hope that was helpful to dive into – we'll dig in a little bit deeper into that side again.
To talk about how we make AI work better for us, let's start with AI.

We'll get into tech-enabled services, but before we chat through specifically tech-enabled services, because I look at that as the next wave of innovation, let’s reflect back on the wave of innovation that we've just gone through over the past roughly 6-7 years (under the traditional trope that innovators and innovative companies deliver a 10x better experience at a fraction of the cost).

We see this with companies like Uber, who completely disrupted the taxi cab industry by solving the problems of security, wait times, convenience, all of that – and while undercutting the cost of cabs.
Airbnb disrupting the hotel industry, Upwork on the freelance side, Netflix, obviously this is a little bit, a little bit longer ago, disrupting how people run in movies.
All of these companies delivered a 10X better experience from the simplicity, from the various different problems their incumbents had, and they did it much cheaper.
And now when we fast forward to what I like to look at as this next wave of startups, the next wave of disruption, we'll call it, there's opportunity for even more.
Here’s a quote from Sarah Tavel, who's a GP at Benchmark, who follows a lot of tech-enabled services companies and who has been leading the charge from the financing side on this wave.

I really like this quote: if the last couple of ways it started felt like 10x improvements, AI provides what feels like a 100x better experience than the incumbent substitute, which is humans, by compressing what is almost always a significant effort of hiring and managing another person into a near-instant experience that will only get better over time.
This is highlighting the sheer amount of gains that are possible when done well. And that “when done well” is obviously the big part here, right? That's the golden goose, so to speak.
One other piece that I want to touch on before we get into the tech is that there's also a lot of business model innovation that goes into this, that needs to match the technological innovation that we're seeing.
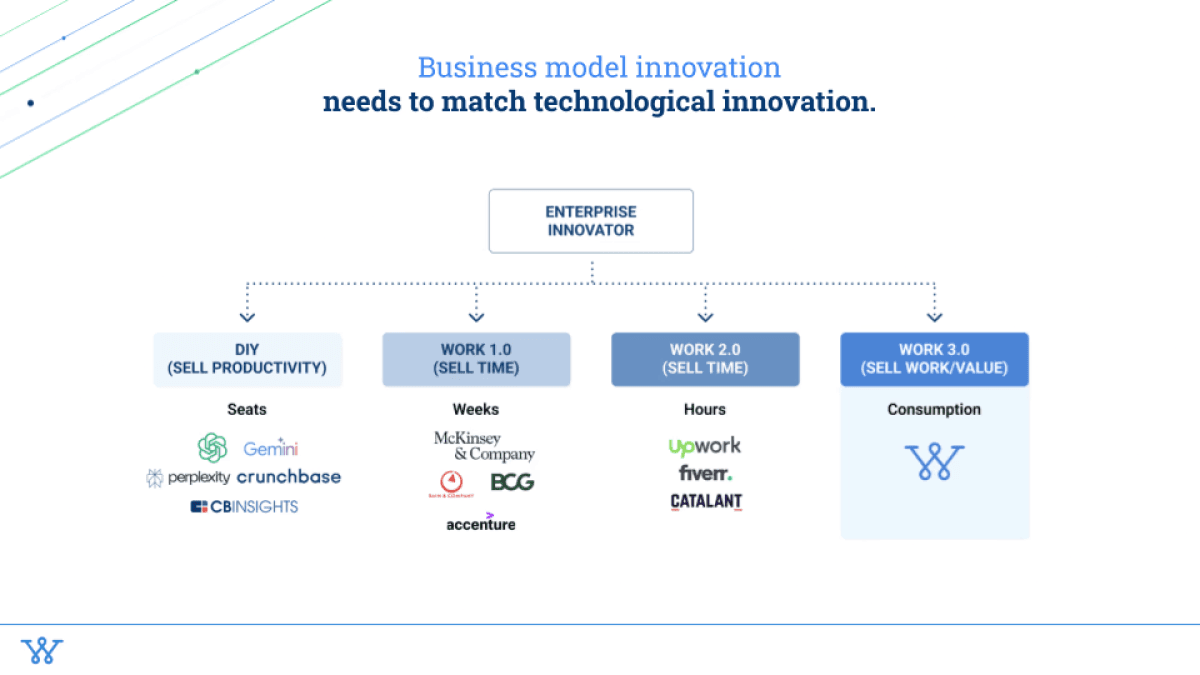
Because if you effectively have the same model, then you’re actually disincentivized from disrupting yourself. For example, if you're selling time, you have no incentive to actually make something more efficient because then you're actually just eating into your own revenue. Your business model needs to change so that it actually maps to the behaviors that you want your internal team to do.
So this is the evolution of how work has evolved over time. Work has gone from “do it yourself,” where you sell productivity, to let's call it Work 1.0, where you sell large chunks of time. McKinsey, BCG, Bain: they’re all selling large month-long, six-month long engagements. To then Work 2.0, which is “how do we now compress that so enterprises and innovation can have a lot more flexibility, and sell hours?” And now, what I call Work 3.0, where you can actually start to sell the work and the value that you're providing because it is much smaller sprints of time (if any amount of time, because there's a lot of AI that goes into it!). So you can start to sell the actual work component more like a consumption-based product, like how AWS or Snowflake prices.
And then this piece (the slide I shared before) around the technology tailwinds that make tech-enabled service models the models of the future. There are these three pretty big tech tailwinds supporting it.
I'm sure everyone's been following the news with NVIDIA and all the public market excitement about everything they're doing.
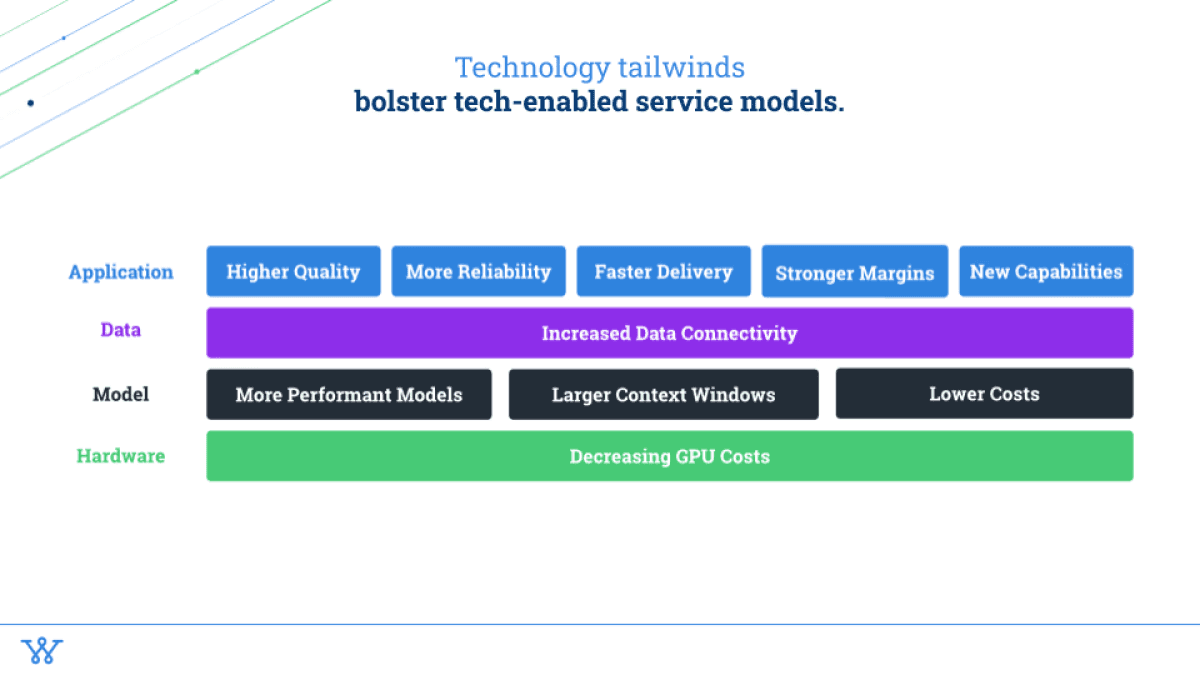
The key piece on the tech-enabled service layer is decreasing GPU costs, which is amazing for model companies. TBD as to whether there'll be a massive model breakthrough or substrate breakthrough in this case with GPUs being significantly cheaper, but even in absence of that, the costs are going down, the supply chain costs are going down, and there are enough people focused on this problem such that we're going to continue to see that cost going down.
Which is great news for model companies because now they can build more performant models. They can give larger context windows (meaning how much information you can feed into an LLM, and then how much information can it spit out). The more information that you can give it, the better off you're going to be with the results that you get from that LLM.
The last piece here is lower costs for the model. What we're seeing across the data layer, now that I've had over 50 conversations with data providers, is that there's more data connectivity happening – increased data accessibility.
Previously, you'd have vendors that would effectively just sell a license to use their data on their platform. A provider like CrunchBase would sell you 10 licenses for $200k a year, and folks that have those licenses could go on and query CrunchBase themselves. They only have access to it.
But what we're now seeing is a lot of these companies are shifting their models to an API-based approach – not just buying specific data sets, but allowing you to pay per data call. Companies like SimilarWeb are really pioneering in that, where you can now actually have a lot more data connectivity that allows for the application layer to win.
And then you're also seeing a lot of internal data connectivity. At Snowflake’s Summit, we're seeing that pretty much every other company here has been focused on how to you make more enterprise data “AI ready,” which really is just how do you make sure we connect that data a lot better such that I can read it and do really cool operations on top of it.
I fully anticipate that to continue to grow over the next couple of years. All that means on the application layer that is built on top of all of this stuff is that you're going to get:
higher quality because you have better models – you have more access to better data,
more reliability because the different AI chains and agents that you build will just be more powerful, so you can give it more instructions,
faster delivery time because you can do a lot more of the work, so you may not need as many human bottlenecks interrupting that supply or insights pipeline,
stronger margins for companies (cheaper costs for customers), and then also
new capabilities, which is a really interesting one, especially as we think about the world of data and the world of research. Historically it's been very text heavy, and that's been the first frontier so to speak.
Now, with a lot of the AI models, we can do a lot more image analysis. And the next one that's going to be really cool to see is video and audio analysis that require a lot more performant models, and even different models. If you saw the Sora model from OpenAI, it's able to create these super human videos, that are all generated by AI.
From the ability to create those videos, we’ll then be analyzing videos and then be able to figure out “How do we derive insights from those videos?” There are definitely some companies popping up in there, but right now the context window size, the capabilities are still growing. But I have full faith that over the next couple of years, those pieces will be another modality that can be supported across the research stack.
Victoria: Before we get into the Wonder side of things, a question from Doug back to the slide comparing the unit of measure for different stakeholders or parties. Doug's question was “For the consultancy bucket, how do we think about the “time” piece different from the value-based deals that some consultants are already deploying where they're billing for outcomes instead of time and expenses?”
I'll say, having worked for a consulting company where we tried to make this switch: the micro unit is still time. It became very difficult, where you're trying to package and make as efficient as possible the time you're spending, because that's ultimately what the outflow on the cost side is for the consulting firm.
Ainesh: It is good to take this step of focusing it on value for the customer, but what's underlying it is a cost plus model to then price out “this is exactly what our costs are and we’re going to reframe it into the value that you get.”
It becomes interesting because then if they're still using an underlying cost plus model, even if they're messaging it as value, you're still not incentivized to adopt AI as much because it is, it is based on a cost plus model.
If instead you're saying, “Hey, wait – we can now get a ton more customers. We actually will take that leap of faith. We're going to double down and commit to value, and we're going to adopt these technologies.” A lot of consultancies that do that and double down on AI and disrupting themselves before they get disrupted will succeed. But it's an excellent question, because consultancies are definitely moving there.
Victoria: The other way to think about it is where the capacity is and your capacity is constrained by the number of people, the physical human hours all of your employees work x even 24 hours a day x seven days a week. At some point which clients you sell to is a function of who will pay a premium for the time that consultancies are able to give, which even if you're billing on the outcome-based piece, there's only so many hours that you can physically allocate to client work as a consultancy.
Whereas – Ainesh, you’ll get into this with Wonder as we made the shift from being human bandwidth-powered to how much more can we get done with agents and AI – even when somebody comes back with a “yes and” or a build on a request, it’s like “we didn't really allocate for an extra four hours to spend on this. So either you're going to have to pay or we're swallowing a cost.” With us, it's more like, “we'll take that as a learning, but we'll also be able to execute without this capacity constraint holding us back.”
Ainesh: Yeah, there are definitely some interesting alternative models around rev share that I've seen from consultancies, which I think is probably in everyone’s best interest because it has that aligned set of interests. But there are also other models.
I think overall business model innovation, I'm bullish on that leading them to the right behaviors.
So a peek under the hood inside the lab!

How does Wonder make AI more useful for professional research?
Before I go into what we do, I want to highlight three high level ways that anyone can improve the output you get from AI.
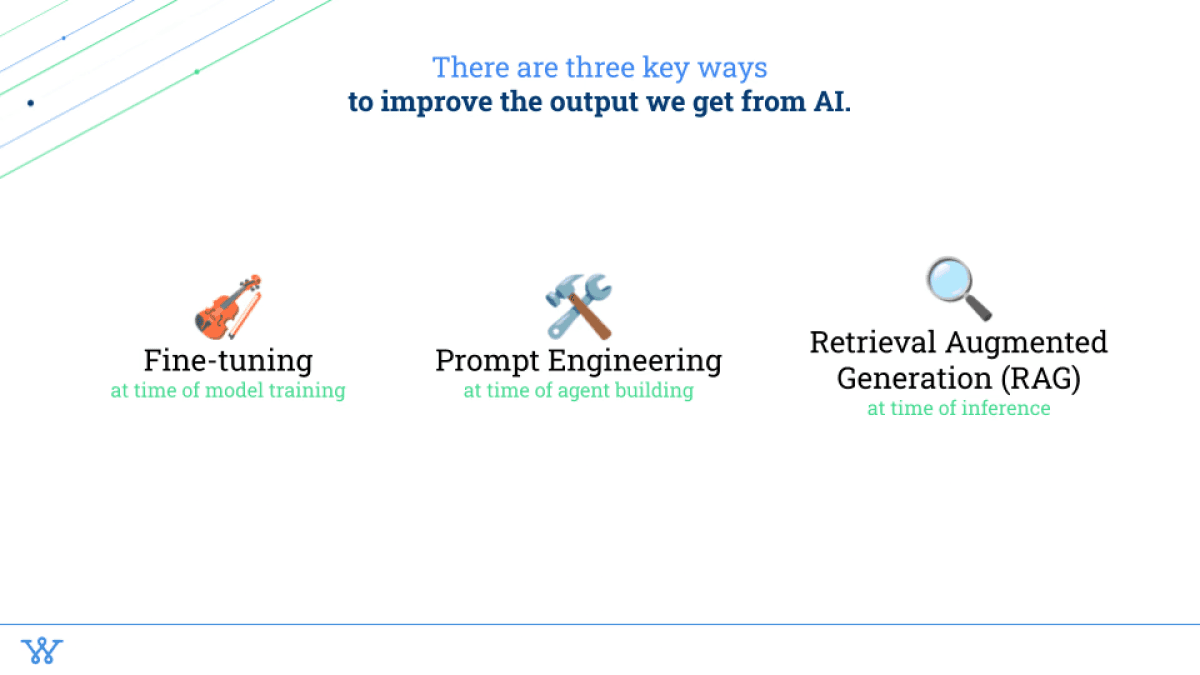
The first one being fine tuning. I'll get into what each of these mean, but fine tuning happens at the time when you actually train a model for a specific use case.
The next being prompt engineering, which happens whenever you have a set of agents or chains, or even just LLM calls that you actually can guide that LLM call or that AI to what you want to do.
And then retrieval augmented generation, which happens at the time of inference (and when I say at the time of inference, what I mean is whenever it's actually being run, what is the data that it has access to?). A way to think about it is “how do you fill the brain that it's using up with the right information to then pull the most accurate stuff from, to then get the most accurate results?”
I'm going to double click into each of these, and share some use cases as to when it could be useful.
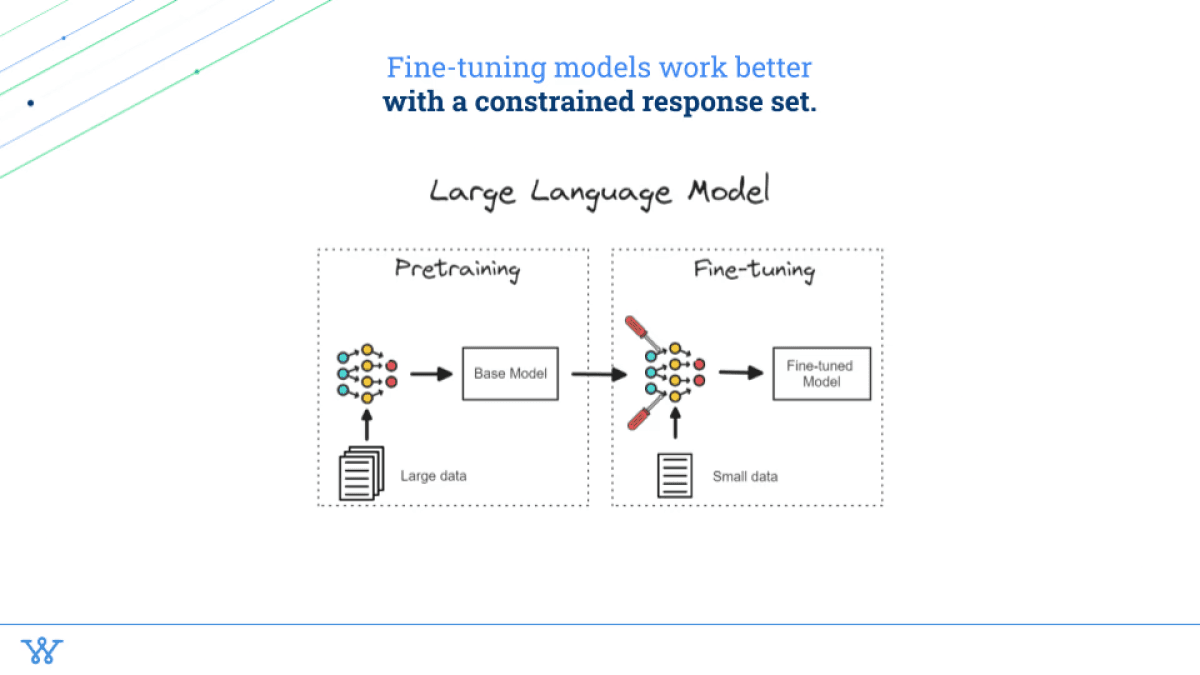
Fine tuning models typically work when you have a constrained response set.
Whenever someone says a pre-trained model, what they mean is the GPT-4 or the Claude-3 family – Haiku, Sonnet, Opus – all of those are pre-trained models. These companies are the model companies. They just spend a lot of money and a lot of time, acquire a lot of data, and then just feed that into a set of transformers that then train this base model. Then, with that base model, what you can do is actually further fine-tune that, so to speak, on a smaller data set.
This is really helpful when you have a constrained set of options that can happen where you can effectively pass in, here's what the input was, here's what the output was, and was it correct or not? And you can effectively feed in a set of 500+ or 1000 – the more data you have, the better – to then get a fine-tuned model.
An example where this could be useful: let's say you're an x-ray technologist and you want to detect if there's a fracture in a bone. There are a couple of different potential outcomes here (it's either fractured or it's not), and you have a set of images that lead to whether it's fractured or it's not.
You don't need the whole training data of the web to tell you whether something is fractured or not. You actually just need a set of images and a set of outcomes to then be able to effectively train a model to then guess whether, based on an image, “does this person have a fracture?”
So that’s an example of when there's a constrained response set and you know what that small data set input looks like, to then get that output data.
Now I want to go into prompt engineering.
I want to highlight: with fine-tune models, in the world of research, because it's not a constrained response set, there are limited use cases that we found where fine-tuning a model actually makes sense. That was the first place we started and we realized it doesn't give a high-enough quality or fidelity of answer for us to use that.
But what did do that was actually the prompt engineering approach, where we effectively took all of the research that we've done and the process by which we did it and we codified everything.
That gave us a massive head start when thinking about actually building these agentic workflows. This is just one example of our competitive landscape workflow. All of these different boxes are different tasks that a research analyst does. There are different decisions we make throughout, which then get translated into an AI agent or chain.
When I say an agent or chain, they're really just different AI paradigms to use – or really data pipelines to use:
An agent goes in a circle; it does some level of reasoning, takes some action, and then based on the result of that action figures out what to do next. You can think of it as a circle that continues to go until you tell it to stop.
A chain, on the other hand, is like an assembly line where there's a definitive starting point, and there's a definitive ending.
Each workflow can contain any amount of agents and chains. It really depends on what you're trying to achieve.

When we think about how we actually go about choosing the right LLM for each part of the workflow, it's one of those things where every LLM is not built the same, and so every LLM has its own home in the workflows. It's not necessarily fair to say “it's always this one, or it's always that one.”
The lighter, faster models that have the highest token limits are incredibly great at taking a lot of data and outputting something super simple about that data. So, for example, if you're just classifying a company based on a set of industries, but you need to give that LLM a ton of information, Claude's lowest model Haiku is fantastic at that. If you want something that's a little bit more on the summarization space, Claude's Sonnet or GPT-3.5. That set of models is really good at taking something and just summarizing it really quickly. It can't take in as much information as Haiku, but it can do a little bit better.
And then you have Opus, or let's call it the GPT-4 / Omni set of models, which do a lot better on the reasoning side – on the most complex tasks where you can't give it too much information, but you need it to reason through and deliver a great analysis. Writing tasks for Opus are just incredible, and following more complex instructions. Those are better for those higher models.
Each part of that pipeline requires its own model that makes it more performant and also just more useful overall. Because if you need to synthesize a lot of data, Opus might not be able to do it, because you run into token context window limits with them.
So really it takes knowing what the overall architecture looks for the agent and then plugging in the LLM for the task.
And now I want to talk about the last component in there, which is RAG or retrieval augmented generation.

This is a quote from Reid Hoffman, founder and ex-CEO of LinkedIn, now the cofounder of inflection AI. To break this down, one of the challenges that a lot of folks have had with a lot of the LLMs – when you're just using ChatGPT, for example – is that it only had access or was only trained on data up until 2023.
And then the question became, “What do we then do for anything innovative that we're working on, which would naturally need more recent information about that thing?” That's where you actually have to look at how you feed the brain the right information. How do you actually execute Google search queries in real time? How do you actually connect to the right data stores in real time to then feed that brain, feed the AI, the right information to then run its synthesis and its reasoning logic on top of?
So that's the basic description of RAG. But when we think about just the data stores, it isn't just the most real time data – it's also the highest quality data.
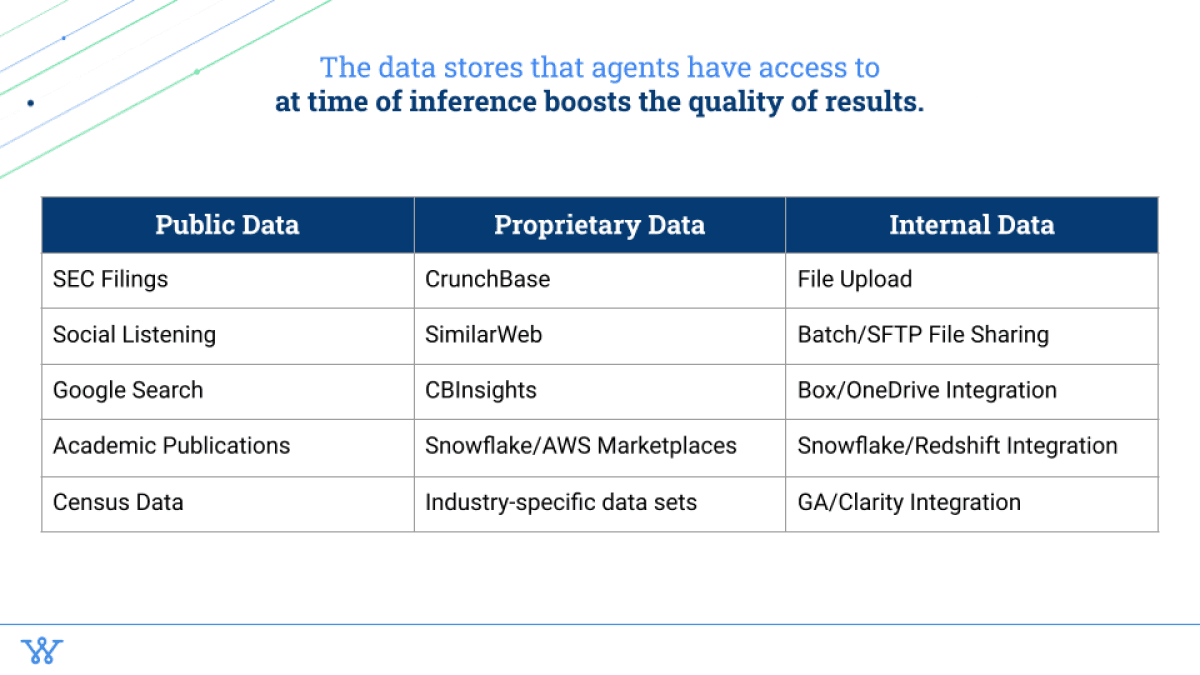
And all of that is happening at time of inference (and again, when I say time of inference, I mean the time that the agent needs to run, when it is dynamically deciding where it should go pull data from). There's a few different classes or categories of data that make sense, especially in the research world.
You have the public data, the proprietary data, and internal data (the company’s). On the public data side, you have SEC filings: how do you scrape 10Ks or 10Qs for all of the latest MD&A that's going on? How do you scrape it for the latest revenues? All of that. Social listening: How do you go into Twitter (X now), LinkedIn, all of that, especially for mining sentiment analysis. Google search: Google still has the largest set of things out there that, especially for press releases, are really great to go through and run a lot of Google searches. Academic publications for things that need a higher level of scrutiny, especially when you're looking at scientific publications or anything that's going from the NCBI database or anything healthcare-related, and then census data. There's a series of different public data sets that exist which – if you can create the right tools to go in and query that information to identify when to go to each of those things, it improves the quality of the results.
From there, you have the proprietary data. Things I've alluded to before like CrunchBase, SimilarWeb, CB Insights … they're just different data set providers (FactSet being another one) where you can effectively create an agent that effectively develops an API for using each of those, and it solves the UX problem with using any of these things that have to do with “Wait, how do I know when to go to what tool? How do I navigate a new service to then use and then augment the research that I'm doing?”
And agents can help solve that problem, where these data companies can now really focus on their bread and butter, which is just high quality data, and the pipeline providers like Wonder and possibly other consultancies can focus on “How do we make sure we combine that proprietary data and those insights into something that's actionable for the user?”
And then we're also seeing a ton of proprietary data that companies are now putting up on Snowflake and AWS marketplaces that make it again much easier on the data connectivity side to then process that information. Industry-specific data sets like IQVIA as well, Quintiles – there's a ton of different industry specific data sets, transaction data, that, depending on the type of customer you serve, you then figure out how the agent then crawls that to bring that in.
All of this is getting more and more accessible. Everything is moving towards the API. The business models are starting to transition to a much more flexible space where you can start to pull a lot of this in. And effectively, all that data is becoming AI ready.
And on the internal side, this is where there's a lot of opportunity. You have the basic stuff, let's call it the building block of just processing a file upload, that's pretty standard, right? Even ChatGPT can solve that problem: whenever someone uploads a file, you can analyze that. Which is wild because a year ago, that was mind-blowing.
The next piece is batch SFTP file sharing where you're sharing a lot more files. How do you run agents in parallel across these different things? Then you have much more integration, like Box, One Drive, whatever their text-based documents are that are associated with the enterprise. How do you now start to pull those into analysis? And then a couple other pieces in here: Snowflake has about 700 of the global 2000 on their platform where more and more of these companies are making their data ready. What that really means is in the cloud, accessible to AI agents, classified and categorized in a way such that AI can make sense of that data. And a lot of these companies are moving to the cloud. That makes it a lot easier to then start to process that internal data.
And then there's a series of different tools that each enterprise uses from Google Analytics to Microsoft Clarity to Segment, you name it. There are all of these different silos of data that exist within these tools where there's going to be a way to get (through an API key) a lot of that data into a place where it can be analyzed by different agents.
A couple of things I want to touch on on the human in the loop side – more so learnings that we've gone through, so hopefully you don't have to go through our hard lessons.
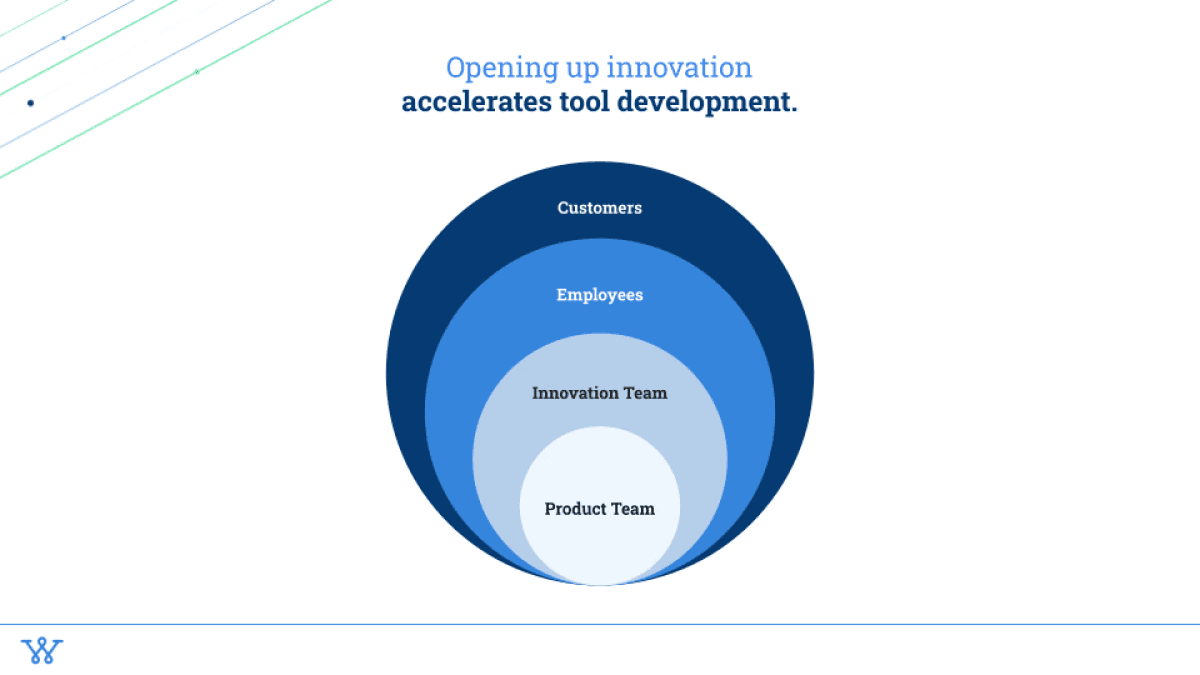
The first one being, how do you open up innovation? And really the crux of it is that opening up all of the innovation that you're building actually accelerates tool development.
We started off in a world where just the product team had access to the agents and chains that we were building. And we realized that software engineers are not great prompt engineers. They're amazing actual engineers to put these things together, but the pod structure itself needs to change where we've actually reorganized internally to have a research expert in our product development pod to have a prompt engineer on our product development pod as well as an RLHF (or reinforcement learning human feedback) engineer do a lot of the testing for everything that we're doing such that we've actually now created this new innovation pod-like structure, where we have all of the perspectives in the room.
Then from there, we opened up to our employees to get real feedback on what we're building. And then, obviously to customers to figure out how the tool is working – and especially experts in the space. One tool we built recently was a tool to scrape through all of the different SEC filings. Can we get financial analysts that actually do this for a living to evaluate the success of the tool and provide different ways that it can get better? The more and more open you can be with this stuff, the faster the team can be.
And the last piece in here is: in the moment itself, how do you include a human in the loop to amplify, evaluate, and train AI agents?
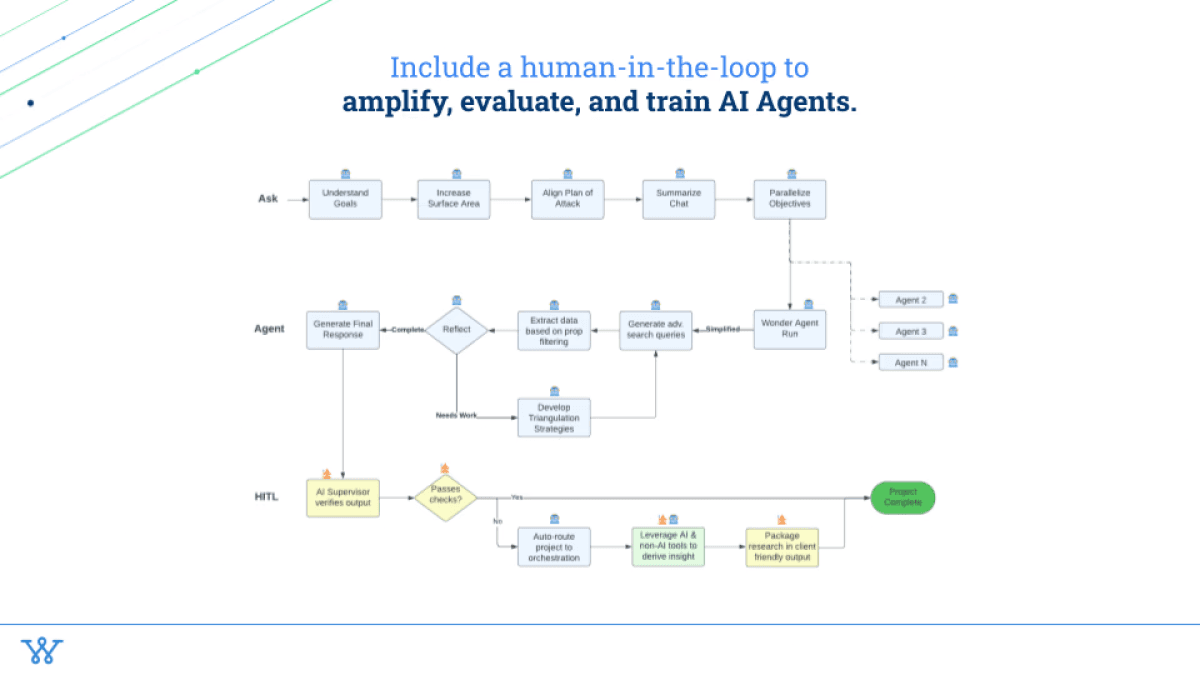
What we've seen is that while we can get our AI agent to +90%, there's still that extra 10% in there where a human in the loop is needed.
And there are also some questions where AI just isn't ready. To help out that much and to be able to provide a full-stack enterprise solution, you need reliability. And the only way to get there is by having the humans in the loop to make sure that what the customer is asking for, they're getting. But it also helps us actually evaluate, “Hey, what is the success of these agents that we're building? How do we improve them?” There are LLM techniques that we're going to be playing with soon to automatically evaluate some of this stuff and help ease that burden on the human side.
And then lastly, to train these agents and identify different opportunities for new AI agents.
When I think about the size of that team, I can only see that team growing because of the amount of work that goes in there is just growing.
We'll call it here! Excited to connect with everyone on LinkedIn and, and keep navigating this wacky world together.